i. Train ResNet18 Model
We will now train ResNet18 model on Tiny ImageNet dataset. The training the will run on two gpu worker nodes in the ray cluster launched in section g.
The python code for the training is mostly standard PyTorch model training code with some additional ray code to set up the distributed training on the ray cluster. Following is the complete code which we will run on the cluster. Create train.py file and copy the code to this file:
(TODO move this code to a downloadable file)
import ray
from ray.train.torch import TorchTrainer
from ray.train.torch import prepare_data_loader, prepare_model
from ray.air.config import ScalingConfig
from ray.air import session
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
def imagenet_data_creator(config):
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(224),
transforms.ToTensor()
])
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
train_data = datasets.ImageFolder(config['traindir'], transform=train_transform)
val_data = datasets.ImageFolder(config['valdir'], transform=val_transform)
train_loader = DataLoader(
train_data,
config['batch_size'],
num_workers=config['num_data_workers'],
pin_memory=True,
shuffle=True
)
val_loader = DataLoader(
val_data,
config['batch_size'],
num_workers=config['num_data_workers'],
pin_memory=True
)
return train_loader, val_loader
def train_epoch(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) // session.get_world_size()
model.train()
for batch, (X, y) in enumerate(dataloader):
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"train loss: {loss:>5f}, batch [{current:>5d}/{size:>5d}]")
def validate_epoch(dataloader, model, loss_fn):
size = len(dataloader.dataset) // session.get_world_size()
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Accuracy: {(100 * correct):>0.1f}%, ", f"Avg loss: {test_loss:>8f} \n")
return test_loss
def train_func(config):
# Create data loaders.
train_dataloader, val_dataloader = imagenet_data_creator(config)
train_dataloader = prepare_data_loader(train_dataloader)
val_dataloader = prepare_data_loader(val_dataloader)
# Create model.
model = models.resnet18()
model = prepare_model(model)
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=config['lr'])
loss_results = []
for _ in range(config['epochs']):
train_epoch(train_dataloader, model, loss_fn, optimizer)
loss = validate_epoch(val_dataloader, model, loss_fn)
ray.train.report(loss=loss)
loss_results.append(loss)
return loss_results
def main(config):
ray.init(address='auto', log_to_driver=True)
scaling_config = ScalingConfig(
num_workers=config['num_ray_workers'],
use_gpu=config['use_gpu'],
resources_per_worker=config['resources_per_worker']
)
trainer = TorchTrainer(
train_func,
train_loop_config=config,
scaling_config=scaling_config
)
result = trainer.fit()
print(f"Loss results: {result}")
if __name__ == "__main__":
config = {
# ray related config
'num_ray_workers': 2,
'use_gpu': True,
'resources_per_worker': {'CPU': 4, 'GPU': 1},
# pytorch related config
'traindir':'/fsx/tiny-imagenet-200/train',
'valdir': '/fsx/tiny-imagenet-200/val',
'batch_size': 64, # per worker batch size
'num_data_workers': 4,
'lr': 1e-3,
'epochs': 1,
}
main(config)
To submit this code to the ray cluster execute the following:
ray submit cluster.yaml train.py
This training job will take 7-8 min for one epoch.
While the job is running, we can monitor gpu usage in CloudWatch. Navigate to CloudWatch console and select All Metric from the left pan. You will find ray-workshop-CWAgent namespace under Custom namespaces. Select this namespace and then click on the first group in the next step. You should see the following metrics for each gpu in the cluster:
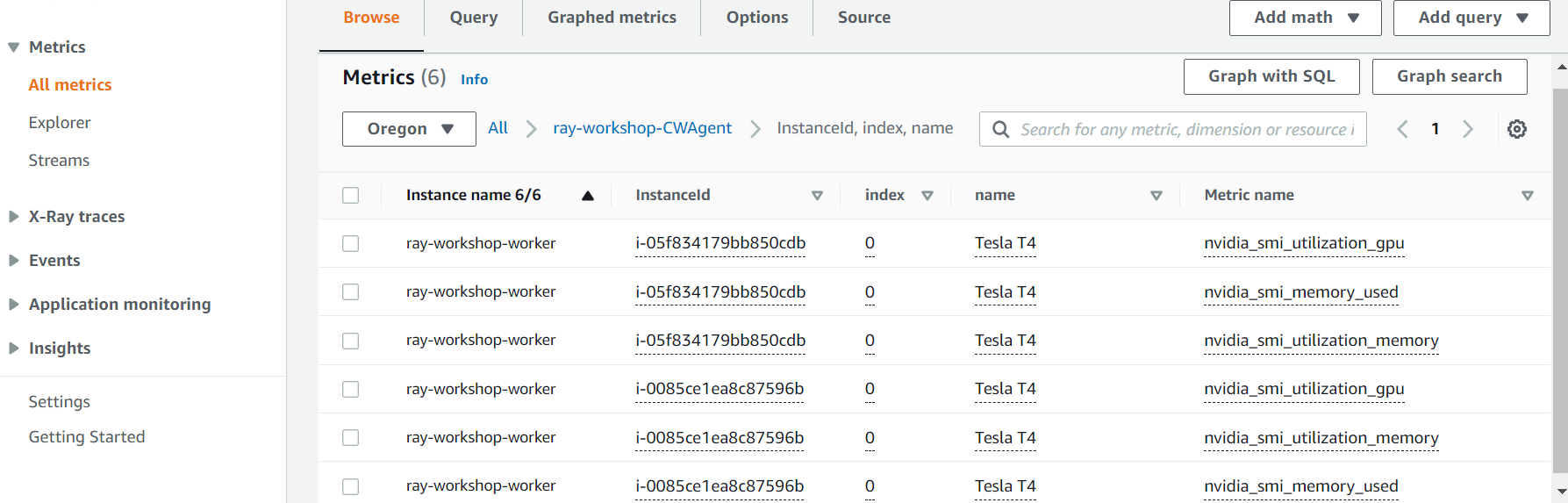
Select the gpu utilization metrics from this list. Next, select Graphed metrics tab and change the averaging time from 5 min to 10 sec. Keep in the mind that it might take several minutes before the gpu utilization will show in the CloudWatch. It takes some time for the training to start on the cluster, and also, CloudWatch metrics are delayed by almost one minute.